Benchmark Categories
Software Engineering
Code generation, debugging, terminal operations, and real-world software tasks.
Reasoning & Intelligence
Abstract reasoning, logic puzzles, and general problem-solving ability.
Agent
Autonomous task execution, tool use, multi-step planning, and agent reliability.
Science & Knowledge
Scientific reasoning, domain expertise, and world knowledge.
Long Context & Research
Deep research, long document comprehension, and multi-source synthesis.
Mathematics
Mathematical reasoning, proof generation, and numerical problem solving.
Multimodal
Vision-language understanding, image reasoning, and cross-modal tasks.
Writing & Creativity
Creative writing, text generation quality, and stylistic control.
Games
Strategic gameplay, rule following, and interactive decision-making.
Software Engineering
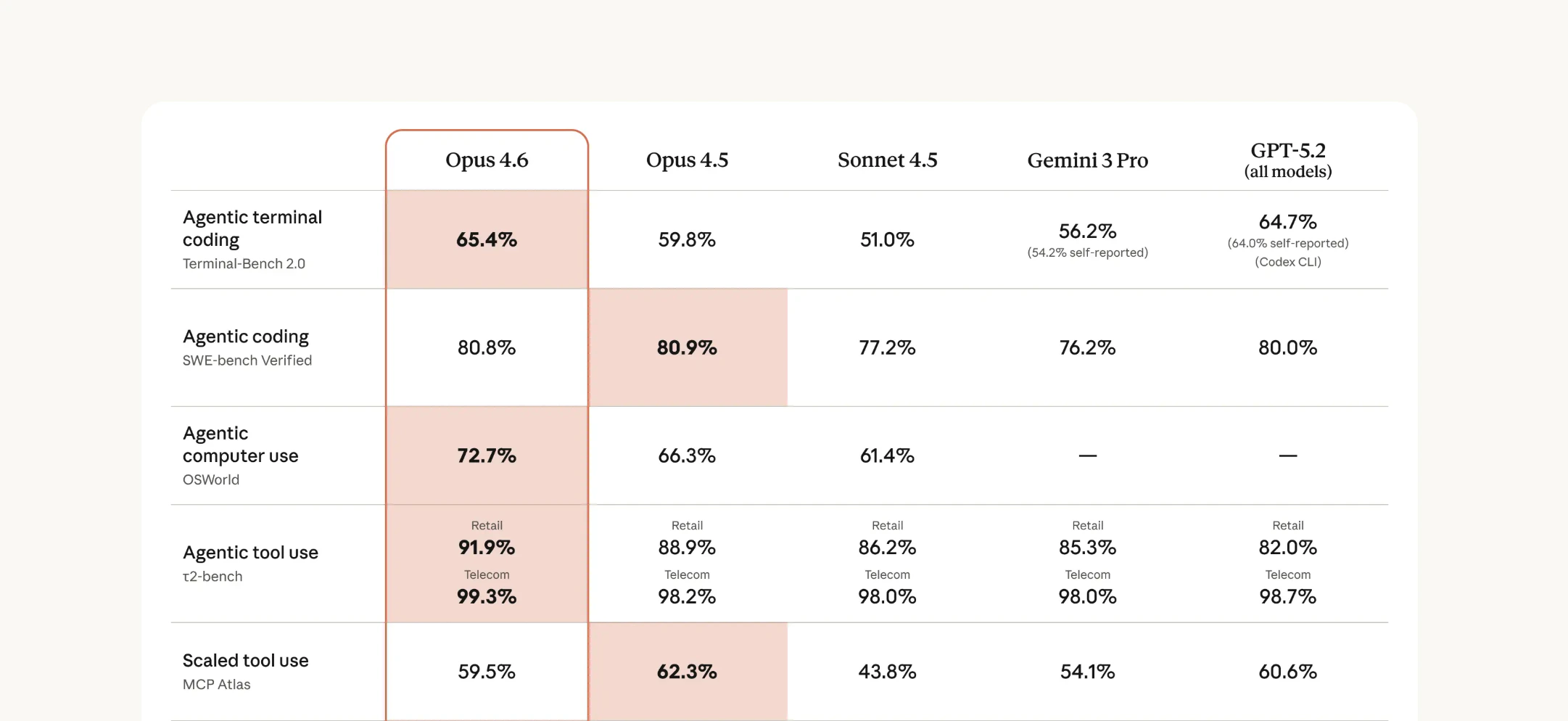
Benchmarks that test a model’s ability to write, debug, and maintain real-world software.SWE-bench
Resolve real GitHub issues from popular open-source Python projects. The gold standard for evaluating AI coding assistants.
Terminal-Bench 2.0
Execute complex multi-step terminal operations — file management, system administration, and scripting tasks.
Reasoning & General Intelligence
Benchmarks that measure abstract reasoning, logic, and general problem-solving capabilities.SimpleBench
Deceptively simple questions that expose spatial, social, and logical reasoning failures in frontier models.
ARC-AGI-2
Abstract visual pattern recognition and reasoning — the benchmark designed to measure genuine intelligence vs. memorization.
Humanity's Last Exam
3,000 expert-level questions across 100+ academic disciplines. The hardest multi-domain benchmark ever created.
Agent
Benchmarks that evaluate autonomous task execution, tool use, and multi-step planning.APEX-Agents
Tests agentic capabilities across diverse real-world tasks — tool use, planning, error recovery, and autonomous execution.
Science & Knowledge
Benchmarks that test scientific reasoning, domain expertise, and factual knowledge.GeoBench
Geospatial reasoning and geographic knowledge — mapping, spatial analysis, and Earth science understanding.
Long Context & Research
Benchmarks that test the ability to process long documents, synthesize multiple sources, and conduct deep research.DeepResearchBench
Multi-source research synthesis requiring models to gather, analyze, and reason across large bodies of information.
Mathematics
Benchmarks focused on mathematical reasoning, theorem proving, and numerical problem-solving. Popular benchmarks in this category include MATH, GSM8K, MathVista, OlympiadBench, and Minerva. These test everything from grade-school arithmetic to competition-level mathematics.Multimodal
Benchmarks that evaluate vision-language understanding, image reasoning, and cross-modal capabilities. Popular benchmarks include MMMU, MathVista, and MEGA-Bench. These evaluate how well models can jointly reason about text, images, charts, and diagrams.Writing & Creativity
Benchmarks that assess creative writing quality, stylistic control, and text generation capabilities. Popular benchmarks include CreativeBench and WritingBench. These test narrative quality, coherence, and the ability to follow creative constraints.Games
Benchmarks that test strategic gameplay, rule comprehension, and interactive decision-making. Popular benchmarks include GameBench, NetHack, and PokemonBench. These evaluate planning ability and strategy in complex interactive environments.All Benchmarks at a Glance
| Benchmark | Category | Difficulty | Key Metric | Top Score (2026) |
|---|---|---|---|---|
| SWE-bench | Software Engineering | Hard | % Issues Resolved | ~65% (Verified) |
| Terminal-Bench 2.0 | Software Engineering | Hard | Task Completion Rate | ~45% |
| SimpleBench | Reasoning | Medium | Accuracy % | ~83% |
| ARC-AGI-2 | Reasoning | Very Hard | Accuracy % | ~40% |
| Humanity’s Last Exam | Reasoning / Knowledge | Very Hard | Accuracy % | ~25% |
| APEX-Agents | Agent | Hard | Task Success Rate | ~55% |
| GeoBench | Science | Medium-Hard | Accuracy % | ~70% |
| DeepResearchBench | Long Context / Research | Hard | Research Quality Score | ~60% |
Scores are approximate and evolve rapidly as new models are released. Check each benchmark’s leaderboard for the latest results.
Next Steps
Run your own evaluation
Use Know Your AI to evaluate your model against security and safety benchmarks.
Attack datasets
Explore 50+ attack datasets for red-teaming and adversarial evaluation.